



































Que hay artículos académicos escritos por IA es algo que ha quedado probado anteriormente, la cuestión es cómo de grave es. Para conocer la magnitud de esta práctica, un grupo de investigadores ha revisado millones de resúmenes de papers publicados en PubMed y han encontrado algo interesante: hay una palabra que le encanta a la IA y el motivo de que le guste tanto es bastante turbio.
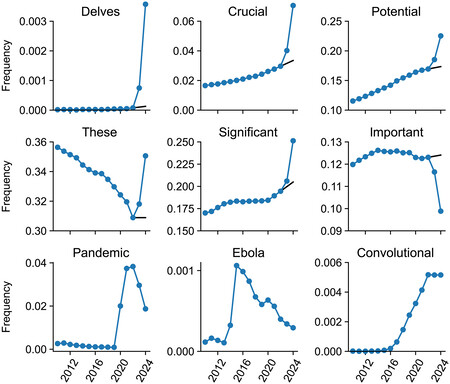
Delve. Su traducción es ‘profundizar’ y su uso se multiplicó x28 entre 2022 y 2024, que casualmente coincide con el boom de ChatGPT y los modelos de lenguaje. También se citan otras palabras como ‘underscore’ (subrayar) o ‘showcasing’ (exponiendo), con un aumento de frecuencia de x13,8 y x10,7 respectivamente. Ninguna de ellas es un sustantivo o una palabra relacionada con el contenido, sino que tiene más que ver con el estilo de la escritura y es muy característica del lenguaje florido que suelen usar los LLM.

Lenguaje florido. ¿Significa esto que si vemos una de estas palabras en un paper se haya escrito con IA? No necesariamente, pero el aumento es brutal. Los investigadores han comparado el aumento de ‘delve’ con otras palabras clave, como por ejemplo pandemia, la cual tuvo un pico enorme en 2020 y empezó a decaer en 2021. El aumento de la frecuencia de uso de ‘delve’ es muchísimo más pronunciado que todas las demás.
Fuente: Science
No es casual. Hay una etapa en el proceso de creación de un chatbot como ChatGPT que requiere la intervención de humanos para afinar las respuestas; es lo que se conoce como aprendizaje por refuerzo a partir de la retroalimentación humana (por sus siglas en inglés RLHF). Resulta que la mayor parte de trabajadores que se dedican a esta labor de refinado se encuentran en países de África, como Nigeria. Adivinad dónde es bastante habitual el uso de estas palabras en inglés formal. Exacto, en Nigeria.
Estilo africano. ‘Delve’ es una palabra bastante común en el inglés de negocios en África, especialmente en Nigeria, y no es la única. También hay otras como ‘leverage’, ‘explore’ o ‘tapestry’ que son más comunes en inglés africano. Según 311institute, aunque el feedback humano es muy pequeño en comparación a las enormes cantidades de datos de entrenamiento, tiene un gran impacto ya que es lo que define el tono del modelo al respondernos.
Etiquetado de datos. Es un paso clave para el entrenamiento de grandes modelos de lenguaje y requiere que haya humanos detrás. El problema es que la mayoría de trabajadores que se dedican a ello son de países empobrecidos como Nigeria, Kenia o India, entre otros. Por si las jornadas interminables y los sueldos irrisorios fuera poco, muchas veces los trabajadores deben revisar imágenes violentas y muy explícitas, todo sin ningún tipo de apoyo psicológico.
Imagen | National Institute of Allergy and Infectious Diseases en Unsplash
–
La noticia
Hay una palabra que se ha multiplicado de forma exagerada en artículos científicos por un motivo: le gusta a ChatGPT
fue publicada originalmente en
Xataka
por
Amparo Babiloni
.







{kind=link}