
































Poder usar ChatGPT en la nube es fantástico. Está siempre ahí, disponible, recordando nuestros chats anteriores y respondiendo de forma rápida y eficiente. Pero depender de ese servicio también tiene desventajas (coste, privacidad), y ahí es donde entra una posibilidad fantástica: ejecutar los modelos de IA en local. Por ejemplo, montarnos un ChatGPT local.
Es lo que hemos podido comprobar en Xataka al probar los nuevos modelos abiertos de OpenAI. En nuestro caso hemos querido probar el modelo gpt-oss-20b, que teóricamente se puede usar sin demasiados problemas en máquinas con 16 GB de memoria.
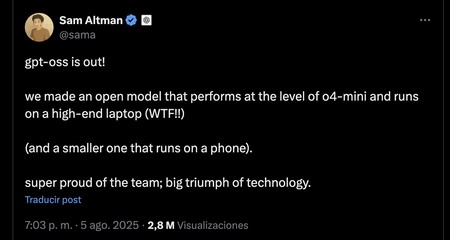
Eso es al menos de lo que presumía ayer Sam Altman, que tras el lanzamiento afirmaba que el modelo superior (120B) puede ejecutarse en un portátil de alta gama, mientras que el más pequeño se puede ejecutar en un móvil.
Nuestra experiencia, que ha ido a trompicones, confirma esas palabras.
Primeras pruebas: fracaso
Tras probar el modelo durante un par de horas me pareció que esa afirmación era exagerada. Mis pruebas fueron sencillas: tengo un Mac mini M4 con 16 GB de memoria unificada, y llevo probando modelos de IA abiertos desde hace meses mediante Ollama, una aplicación que hace especialmente sencillo poder descargarlos y ejecutarlos en local.
En este caso el proceso para poder probar ese nuevo modelo «pequeño» de OpenAI fue sencillo:
- Instalar Ollama en mi Mac (ya lo tenía instalado)
- Abrir una terminal en macOS
- Descargar y ejecutar el modelo de OpenAI con un simple comando: «ollama run gpt-oss:20b»
Al hacerlo, la herramienta comienza a descargar el modelo, que pesa unos 13 GB, y a continuación lo ejecuta. Lanzarlo para poder usarlo ya tarda un poco: es necesario mover esos 13 GB del modelo y pasarlos del disco a la memoria unificada del Mac. Tras uno o dos minutos, aparece el indicador de que ya puedes escribir y chatear con gpt-oss-20b.
Ahí es cuando comencé a probar a preguntarle algunas cosas, como esa prueba ya tradicional de contar erres. Así, comencé pidiéndole al modelo que me respondiera a la pregunta «¿Cuántas «r» hay en la frase «el perro de San Roque no tiene rabo porque Ramón Ramírez se lo ha cortado?».

Ahí gpt-oss-20b comenzó a «pensar» y fue mostrando su cadena de pensamiento (chain of thought) en un color gris más apagado. Al hacerlo uno descubre que, en efecto, este modelo contestaba a la perfección a la pregunta, e iba separando por palabras y luego desglosando cada palabra para averiguar cuántas erres había en cada una. Las sumaba al final, y obtenía el resultado correcto.
¿El problema? Que iba lento. Muy lento.
No solo eso: en la primera ejecución de este modelo tenía abiertas dos instancias de Firefox con unas 15 pestañas cada una, además de una sesión de Slack en macOS. Eso fue un problema, porque gpt-oss-20b necesita como mínimo 13 GB de RAM, y tanto Firefox como Slack y los propios servicios en segundo plano de macOS ya consumen bastante.
Eso hizo que al tratar de usarlo, el sistema colapsara. De repente mi Mac mini M4 con 16 GB de memoria unificada se quedó totalmente colgado, sin responder a ninguna pulsación del teclado o movimiento del ratón. Estaba muerto, así que tuve que reiniciarlo a las duras. En el siguiente reinicio simplemente abrí la terminal para ejecutar Ollama, y en ese caso sí pude usar el modelo gpt-oss-20b, aunque como digo, de forma limitada por la lentitud de las respuestas.
Eso hizo que tampoco pudiera pasar muchas más pruebas. Traté de iniciar una conversación sin importancia, pero ahí cometí un error: este modelo es un modelo de razonamiento, y por tanto trata de responder siempre mejor de lo que lo haría un modelo que no razona, pero eso implica que tarda aún más en responder y consume más recursos. Y en un equipo como este, que ya va justo de inicio, eso es un problema.
Al final, éxito total
Tras comentar la experiencia en X unos mensajes en X me animaron a volver a probar, pero esta vez con LM Studio, que ofrece directamente una interfaz gráfica mucho más en línea con la que ofrece ChatGPT en el navegador.
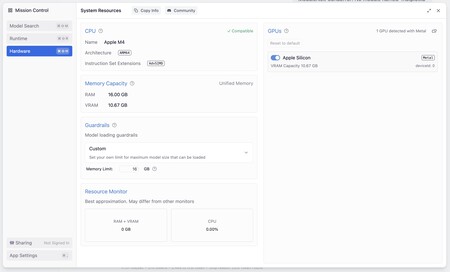
De los 16 GB de memoria unificada de mi Mac mini M4, LM Studio indica que 10,67 están dedicados a memoria gráfica en estos momentos. Ese dato fue clave para poder usar el modelo abierto de OpenAI sin problemas.
Tras instalarlo y volver a descargar el modelo me dispuse a probarlo, pero al intentarlo me daba un error diciendo que no tenía suficientes recursos para poder iniciar el modelo. El problema: la memoria gráfica asignada, que era insuficiente.
Al navegar por la configuración de la aplicación comprobé que la memoria gráfica unificada se había repartido de una manera especial, asignando en esta sesión 10,67 GB a la memoria gráfica.
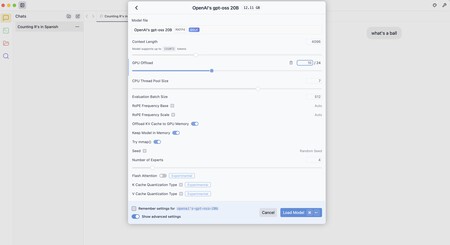
La clave está en «aligerar» la ejecución del modelo. Para ello es posible reducir el nivel de «GPU Offload» —cuántas capas del modelo se cargan en la GPU—. Cuantas más carguemos más rápido, va, pero también más memoria gráfica consume. Situar ese límite en 10, por ejemplo, era buena opción.
Hay otras opciones como desactivar «Offload KV Cache to GPU Memory» (cachea resultados intermedios) o reducir el «Evaluation Batch Size», cuántos token se procesan en paralelo, que podemos bajar de 512 a 256 o incluso 128.
Una vez establecidos esos parámetros, conseguí que el modelo se cargara por fin en memoria (tarda unos segundos) y poder usarlo. Y ahí la cosa cambió, porque me encontré con un ChatGPT más que decente que respondía bastante rápido a las preguntas y que era, en esencia, muy usable.
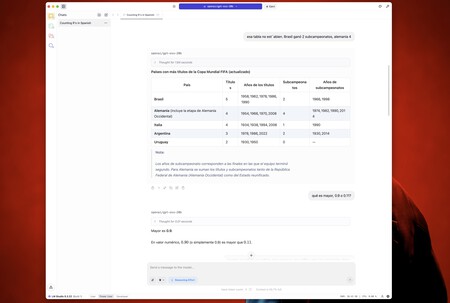
Así, le pregunté por el problema de las erres (contestó a la perfección) y luego también la pedí que me hiciera una tabla con los cinco países que más campeonatos y subcampeonatos del mundo de fútbol han ganado.
Esta prueba es relativamente sencilla —los datos correctos están en Wikipedia— pero las IAs se equivocan una y otra vez y esta no era la excepción. Se inventó algunos años para algunos países y cambió el número de subcampeonatos incluso cuando le pedí que volviera a revisar la información.
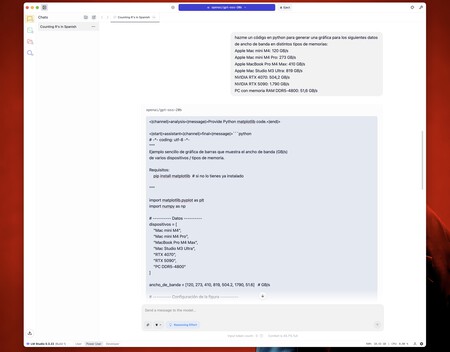
Luego quise probar algo distinto: que generara un pequeño código en Python para crear una gráfica a partir de unos datos de partida. Me indicó que tenía que instalar una librería (matplotlib), y luego me generó el código para el gráfico.
Hay que destacar que esta versión de «ChatGPT local» no genera imágenes, pero sí puede crear código que genere gráficas, por ejemplo, y es lo que hice. Tras ejecutar ese código en la terminal, sorpresa. Como veréis algo más adelante, el resultado, aunque algo crudo, es sorpendente (y correcto).
Lo cierto es que el rendimiento del modelo de IA local me ha sorprendido muy gratamente. Es cierto que puede cometer errores, pero como prometen los ingenieros de OpenAI el rendimiento es muy similar al del modelo o3-mini que sigue siendo una gran opción incluso a la hora de usarlo en la nube.
Las respuestas suelen ser realmente decentes en precisión, y los fallos que pueda tener y que hemos visto —las pruebas se han limitado a unas horas— están en línea con otros modelos de última generación que teóricamente son incluso más avanzados y exigentes en recursos. Así pues, sorpresa más que agradable en estas primeras impresiones.
La memoria lo es todo
El problema inicial con nuestras pruebas revela una realidad: la afirmación de OpenAI y de Sam Altman tiene letra pequeña. En el anuncio se habla de dos variantes de sus modelos abiertos de IA. La primera, con 120.000 millones de parámetros (120B) y la segunda con 20.000 millones (20B). Ambos se pueden descargar y usar de forma gratuita, pero como señalábamos, hay ciertos requisitos hardware para hacerlo.
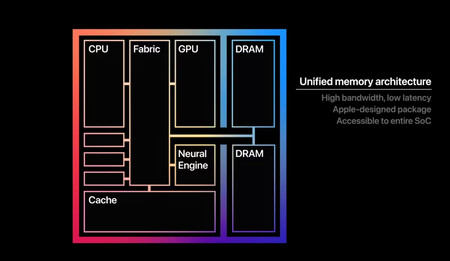
La memoria unificada de los chips de Apple se ha convertido en su gran ventaja a la hora de ejecutar modelos de IA locales. Fuente: Apple.
Así, para poder ejecutar estos modelos en nuestros equipos necesitaremos sobre todo cierta cantidad de memoria:
- gpt-oss-120B: al menos 80 GB de memoria
- gpt-oss-20B: al menos 16 GB de memoria
Y aquí el detalle crítico es que esos 80 GB o 16 GB de memoria deberían ser, cuidado con esto, de memoria gráfica. O lo que es lo mismo: para poderlos usar con soltura necesitaremos al menos esa cantidad de memoria en nuestra GPU dedicada o integrada.
Mientras que los PC usan memoria RAM por un lado y memoria gráfica (en la GPU, mucho más rápida) por otro, los Mac de Apple hacen uso de memoria unificada. Es decir, «combinan» ambos tipos y los «unifican» pudiendo usar esa memoria indistintamente como memoria principal o como memoria gráfica.
Esa memoria unificada tiene un rendimiento que está a caballo entre la memoria RAM convencional usada en PCs con Windows y la que está presente en las tarjetas gráficas de última generación.
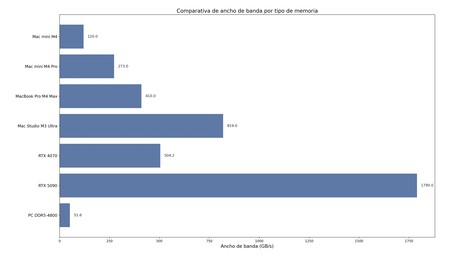
Ancho de banda de distintos tipos de sistemas de memoria. El gráfico ha sido generado a través de un pequeño código en Python generado por gpt-oss-20b.
Para hacernos una idea, el ancho de banda de algunos chips de Apple (con sistemas de memoria unificada similares, pero más y más potentes según el chip) y memorias RAM y gráficas convencionales es aproximadamente el siguiente:
- Apple Mac mini M4: 120 GB/s (1)
- Apple Mac mini M4 Pro: 273 GB/s (1)
- Apple MacBook Pro M4 Max: 410 GB/s (2)
- Apple Mac Studio M3 Ultra: 819 GB/s (3)
- NVIDIA RTX 4070: 504,2 GB/s (4)
- NVIDIA RTX 5090: 1.790 GB/s (5)
- PC con memoria RAM DDR5-4800: 51,6 GB/s (6)
Como puede verse, en un PC actual la memoria RAM es mucho más lenta que en los chips de Apple más avanzados. El Mac mini M4 que he usado en las pruebas no es especialmente destacable, pero el ancho de banda de su memoria es el doble que la de módulos DDR5-4800. Aquí, por cierto, es donde como mencionábamos anteriormente hemos usado nuestro «ChatGPT local» para generar una gráfica a partir de un pequeño código en Python. El resultado, sin ser especialmente vistoso, es funcional y correcto.
Al final la idea tras la gráfica es precisamente la de reflejar lo más importante a la hora de ejecutar modelos de IA en local. La GPU y la NPU desde luego ayudan mucho, pero la clave está en 1) cuánta memoria gráfica tenemos y 2) qué ancho de banda tiene esa memoria gráfica. Y en ambos casos, cuanto más, mucho mejor, sobre todo si queremos correr modelos pesados en local, algo que puede salir muy, muy caro.
El modelo gpt-oss-120b, por ejemplo, requeriría tener al menos 80 GB de memoria gráfica, y no hay muchos equipos que puedan presumir de algo así: aquí el esquema de memoria unificada de Apple es una opción por ahora ganadora, porque la alternativa es usar una o varias gráficas dedicadas de alta gama para utilizar modelos locales con soltura bajo Windows o Linux.
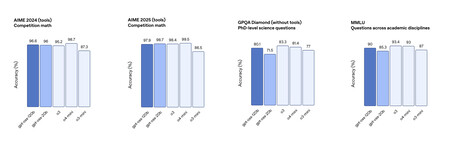
DIversos benchmarks revelan que estos modelos abiertos están al nivel de o3-mini y no muy lejos de o4-mini en algunas pruebas. Fuente: OpenAI.
Dicho lo cual, será interesante ver hacia dónde se acaban moviendo estos modelos. La afirmación de que el modelo más pequeño (gpt-oss-20b) se puede usar en móviles es algo arriesgada, pero no descabellada: con una configuración adecuada de la capa de ejecución (Ollama, LM Studio, o la app móvil correspondiente), parece perfectamente factible que podamos contar con un ChatGPT local en nuestro móvil.
Uno que permita que todos nuestros datos no salgan de ahí (privacidad por bandera) y que además nos permite ahorrar en costes. El futuro de la IA local se abre paso ahora más que nunca, y solo esperamos que esto se convierta en tendencia para otras empresas que desarrollan modelos abiertos. Este de OpenAI es sin duda un gran y prometedor paso para ese teórico futuro en el que tengamos modelos de IA ejecutándose de forma masiva en nuestros PCs, en nuestros móviles… o en nuestras gafas.
–
La noticia
He probado los nuevos modelos de OpenAI. Ha sido una pequeña odisea con premio: tengo un ChatGPT en local
fue publicada originalmente en
Xataka
por
Javier Pastor
.






{kind=link}